
The interface that dissolves when you're done with it
Lily Chambers explores Google's protocol for agent-assembled screens
As AIFLLL readers know, Lily Chambers generally does the Reading Room book reviews. This week, she shifts her focus to something she is passionate about. I recognize that for some readers, this is more technical than usual, however, she includes a section “What the non-technical reader should know”.
Lily writes about A2UI, a new user interface protocol released by Google late last year that lets AI agents generate the interface a user sees in real time: not just the words, but the buttons, forms, and controls, assembled for your specific task and dissolved when you’re done. The technical details are in the essay; what I want to flag before you read is the larger shift she’s describing.
For most of the history of software design, someone built the interface before you arrived. A team of people, working months ahead, decided what you would see and in what order. A2UI is part of a move in which the agent makes those decisions, in the moment, based on inferences about your task.
Her phrase for it is one I find equally fascinating and scary: you don’t navigate to the interface anymore, the interface comes to you. This means AI agents will be designed to ‘auto-configure’ a user interface specific to your needs. And this means AI is not only in control of the knowledge it’s been trained on, but also able to define, filter, and adjust ‘how’ you see information on your personal screen.
She is a conversational AI designer, which means she writes from inside the question rather than around it. Her framing isn’t alarm, and it isn’t boosterism. It’s an attempt to stay clear-eyed about what changes when the system deciding what you see is itself a model output, and who gets to define what “right” means in that context.
She closes on a question, not a verdict. It’s the right one.
Contents:
A2UI - what’s it all about
What A2UI actually is
Why this shifts the design narrative
What this means for enterprise practitioners
What the non-technical reader should know
The design frontier is moving
A2UI - what’s it all about
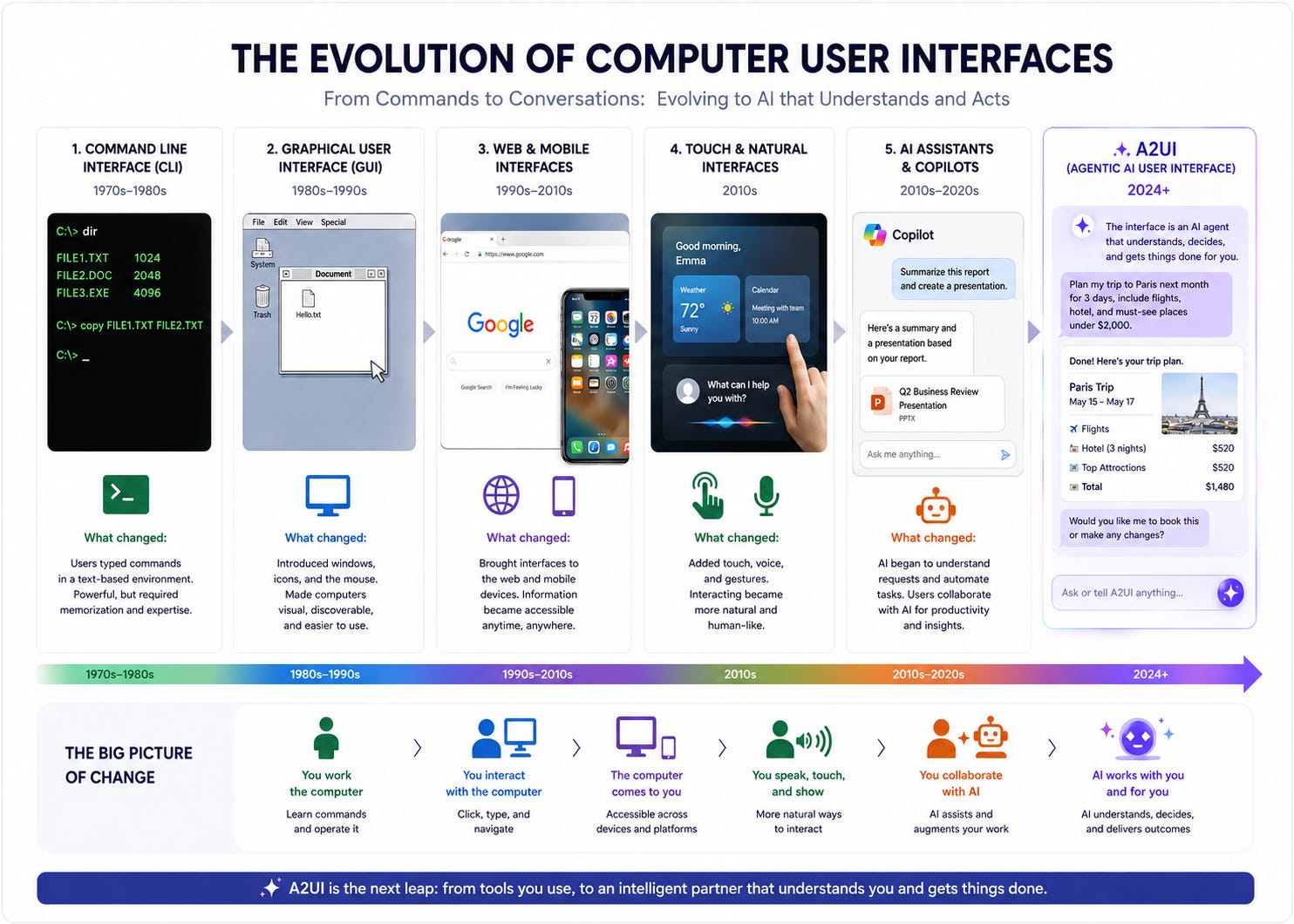
There’s a theory in the world of interface design that platforms shift dramatically every 15 years. Look for 15 year cycles, and you’ll find a meaningful change. We had the personal computer, then mobile devices, then conversational AI. But this timeline is perpetually becoming more rapid as AI remixes the way we think about the boundaries of interface design; we’re moving into a world where we’re departing from the standard idea of designing for the interaction between a human user and a computer model, and instead considering what happens and how do interactions occur between two (or more!) interfaces alone?
I’ve been a conversational AI designer for nearly ten years, and in the last year or so, my work has started to migrate meaningfully into agentic design, the practice of designing systems where AI agents act, decide, and interact not just with humans but with machines, APIs, and other AI agents. It’s a shift that has forced me to reconsider almost everything I thought I knew about design.
The foundational principles of HCI (Human-Computer Interaction) have, for decades, been built around a dyad: one human, one machine. A screen. A cursor. A form. A chat window. Something we talk about in design rooms is the “human factor” of design. How does the human fit into this? How do we thoroughly understand our end user, a human? Even conversational AI, for all its novelty, followed this logic. You [human] type. The model [computer] responds. Back and forth. Turn after turn.
A2UI (Agent-to-User Interface), a protocol released publicly by Google in December 2025, is one of the clearest signals yet that this dyad is dissolving. And if you’re designing for conversational AI at an enterprise level and even just using these tools every day, it’s worth paying attention.
What A2UI actually is
Let’s be precise, because the name itself does a lot of the work. A2UI stands for Agent-to-User Interface. It is an open-source protocol that allows AI agents to generate the interface a user sees. Not just the text inside it, but the buttons, forms, charts, sliders, and interactive components, dynamically, in real time, based on the conversation at hand.
The way most agent-based systems work today is that an agent responds in text. Always text. You ask your AI assistant to help you book a meeting, and it writes back: “What date works for you? What time zone are you in? How long should the meeting be?” It’s functional. It’s also, frankly, tedious, especially in enterprise contexts where these interactions happen at scale.
A2UI changes this. Instead of responding with a paragraph of questions, the agent generates a structured JSON payload. In other words, a description of the interface it wants the user to see. Your application reads that payload and renders it using its own native components: a date picker, a time selector, a dropdown for attendees. The agent never sends executable code. It sends a description, and the client “decides” how to draw it. This matters enormously from a security standpoint. UI as data, not code, means agents can safely operate across trust boundaries, including in multi-agent environments where an orchestrating agent may be delegating tasks to remote agents from a completely separate organization.
Technically, A2UI uses a flat, adjacency-list structure rather than a nested DOM-like hierarchy. Sorry, I got a little technical here. This design choice is deliberate and smart: language models notoriously struggle to generate deeply nested JSON reliably. The flat structure is far more aligned with how transformers produce sequential output, which means fewer errors, less prompt engineering gymnastics, and more consistent results. The protocol is also framework-agnostic; the same A2UI JSON payload can render on Angular, Flutter, React, SwiftUI, or anything else your client uses. And it streams, meaning users see the interface building in real time rather than waiting for a complete response.
Why this shifts the design narrative
This is where I want to slow down, because the implications for design are significant in ways that go beyond the technical.
For as long as I’ve been doing this work, and really for as long as HCI has existed as a discipline, design has been fundamentally about navigation. You build a journey, (my favorite is building “happy paths”) a path through an interface, and the user follows it. Even in conversational design for voice interfaces, where there is no literal screen to navigate, we still design flows: this intent leads to this response, which leads to this follow-up, which resolves here. We draw diagrams. We map intents to entities. We anticipate what a user might say and script the system’s response accordingly.
A2UI, and the broader shift toward agentic design, inverts this logic almost entirely. You don’t design paths anymore. You design guardrails. The agent determines, in real time, what the user needs to see and generates the interface accordingly. Once the task is complete, that interface dissolves. No persistent navigation. No pre-built templates for every scenario. The interface is contextual, ephemeral, and agent-authored.
As one analysis of A2UI aptly put it: you don’t navigate to the interface anymore, the interface comes to you.
This is a paradigm shift with enormous consequences for enterprise deployments. Enterprise conversational AI has historically been constrained by the cost of designing and maintaining conversation flows. Every new use case required a new design. Every edge case had to be anticipated and mapped. A2UI suggests a future where agents surface the right interface for the right task dynamically, reducing that design overhead considerably, but also demanding that designers think differently about their role.
What this means for enterprise practitioners
(If you are a more non-technical reader, keep scrolling, there’s something for you below.)
If you’re building or maintaining conversational AI systems in an enterprise context, A2UI introduces both opportunities and obligations.
On the opportunity side: the reduction in multi-turn friction is meaningful. Tasks that currently require five or six conversational exchanges, such as filling out a form, scheduling a resource, approving a workflow, can potentially be collapsed into a single, contextually generated interface. This isn’t just faster; it’s more accurate. Text-based exchanges introduce ambiguity at every turn. A form with a date picker doesn’t. In high-compliance environments where precision matters like healthcare, finance, legal, this reduction in conversational ambiguity is not trivial.
There’s also the multi-agent dimension to consider. Enterprise AI deployments are increasingly moving toward mesh architectures, where multiple specialized agents collaborate on complex tasks. A2UI was explicitly designed for this: a remote agent, operating within a completely separate organization’s infrastructure, can send A2UI responses that a host application renders safely using its own trusted component library. The security model is built in, not bolted on.
On the obligation side: agentic design requires us to think seriously about what I’d call confirmation friction, the deliberate design of moments where the system slows down and asks for human approval. When an agent is about to trigger a database migration, send a communication on behalf of a user, or execute an irreversible action, the interface must shift modes. The approachable assistant becomes a compliance officer. A2UI can facilitate this, agents can generate explicit Approve/Reject components for high-stakes actions, but the design of when and how those moments occur is still a deeply human responsibility.
This is the part of agentic design that I find both most exciting and most unsettling. The question of “who is responsible when an agent acts incorrectly?” is not answered by the protocol. It’s answered by the people who design the guardrails, define the trust boundaries, and decide which actions require human confirmation and which do not. We are moving, again, from designing paths to designing the shape of the space the agent operates within.
What the non-technical reader should know
If you’re not building these systems but simply living in them or using them more passively, like using AI assistants in your workplace software, interacting with customer service chatbots, or navigating AI-powered apps, A2UI represents a meaningful change in what your experience of those tools will look like.
The shift is, in some ways, toward something more intuitive. Less “talk to the robot” and more “the robot shows you what you need.” Instead of a wall of AI-generated text, you may increasingly find that AI tools surface the right form, the right button, the right control, exactly when you need it. This is genuinely useful. In short, your experience as an end user should be better.
But it also means more of your digital environment will be generated on-the-fly by agents making real-time decisions about what you should see. The interface itself becomes a model output. And as with any model output, it’s worth asking the question I always come back to: optimized for whose benefit?
A2UI’s security model, at least, is thoughtful. Agents reference a client-controlled catalog of approved components, they can’t inject arbitrary UI or execute scripts. But the logic of which interface gets generated, under which conditions, remains the province of the systems deploying it. An agent that generates a frictionless “Confirm purchase” button versus one that generates an “Are you sure? Here are the terms” modal represents the same technical capability applied very differently.
This is not a reason to be alarmed. It’s a reason to remain curious and attentive and to notice when the interface doing the persuading is one you didn’t ask to build. As with the adoption of heavy reliance on any AI tool, as I often tell my teammates and friends, “don’t turn off your brain.”
The design frontier is moving
I’ll admit that when I first encountered A2UI, my instinct was to put it in the “interesting but not yet urgent” pile. I was wrong about that. The protocol is already live in Google Opal and Gemini Enterprise deployments. Version 0.9 shipped in April 2026 with prompt-first generation, bidirectional messaging, and a new Agent SDK. The pace is not slowing. Remember that perpetually more rapid claim I made? Yeah, it’s true.
What I find most worth sitting with is this: HCI has always assumed the human is the one navigating. The interface is the map; the user holds it. Agentic design, and A2UI specifically, suggests a future where the map redraws itself around you in real time, assembled by a system reasoning about your context, your task, your moment of need.
That’s extraordinary. It’s also a fundamentally different relationship between users and the systems they inhabit than anything HCI originally accounted for.
The design question for the next decade is not “what does the user need to click?” It’s “what does the agent need to know in order to generate the right interface, and who has the power to define what ‘right’ means?”
That question, like most of the good ones in this field, doesn’t have a clean answer yet. But it’s the one I’m carrying into every design conversation (or conversation design) I’m in. I’d encourage you to carry it too.
Lily Chambers is a conversational AI designer and writer. She writes at Lingua Machina and AI for Lifelong Learners on Substack (usually just the Reading Room segment.)
Addendum:
A2UI v0.9: The New Standard for Portable, Framework-Agnostic Generative UI
Also, check out Google’s new A2UI Theater for a replay or dive into the A2UI.org for docs, samples and dev guides to start building flexible, portable generative UIs today.
Excellent and thought provoking information giving me insight into an area not considered before. Thank you!
WOW! To quote Spock, with one raised eyebrow, "Fascinating". This is sooo interesting and is such a significant development (pun intended). Thank you for sharing! Excellent as usual.